Cursor’s latest Bugbot update is more than a product tweak. It is a sign that AI code review is entering a new phase: the era of self-improving review systems. In a post published today, Cursor says Bugbot now learns from live feedback and converts that feedback into learned rules. In practice, that means the tool is no longer just scanning pull requests and emitting findings. It is using how developers react to those findings to shape future reviews.
That sounds like a subtle change, but it is actually a major shift in how AI-assisted development tools evolve. The early story of AI coding was mostly about generation: write the boilerplate, draft the function, summarize the file, suggest the patch. Then came the next wave: agents that could inspect repositories, open files, run tests, and take actions. Bugbot points to the next frontier after that. It is not just doing work. It is learning from the work it does inside a real engineering workflow.
For teams shipping software today, that matters for one simple reason: review quality has become a bottleneck. The more code organizations generate, the more they need systems that can separate real issues from noise. If the review layer is noisy, developers tune it out. If it is too conservative, it misses the bugs that matter. Cursor’s pitch is that Bugbot is starting to get better at this balancing act by learning from how teams actually respond in practice, not just from offline benchmarks.
What Cursor says the numbers show
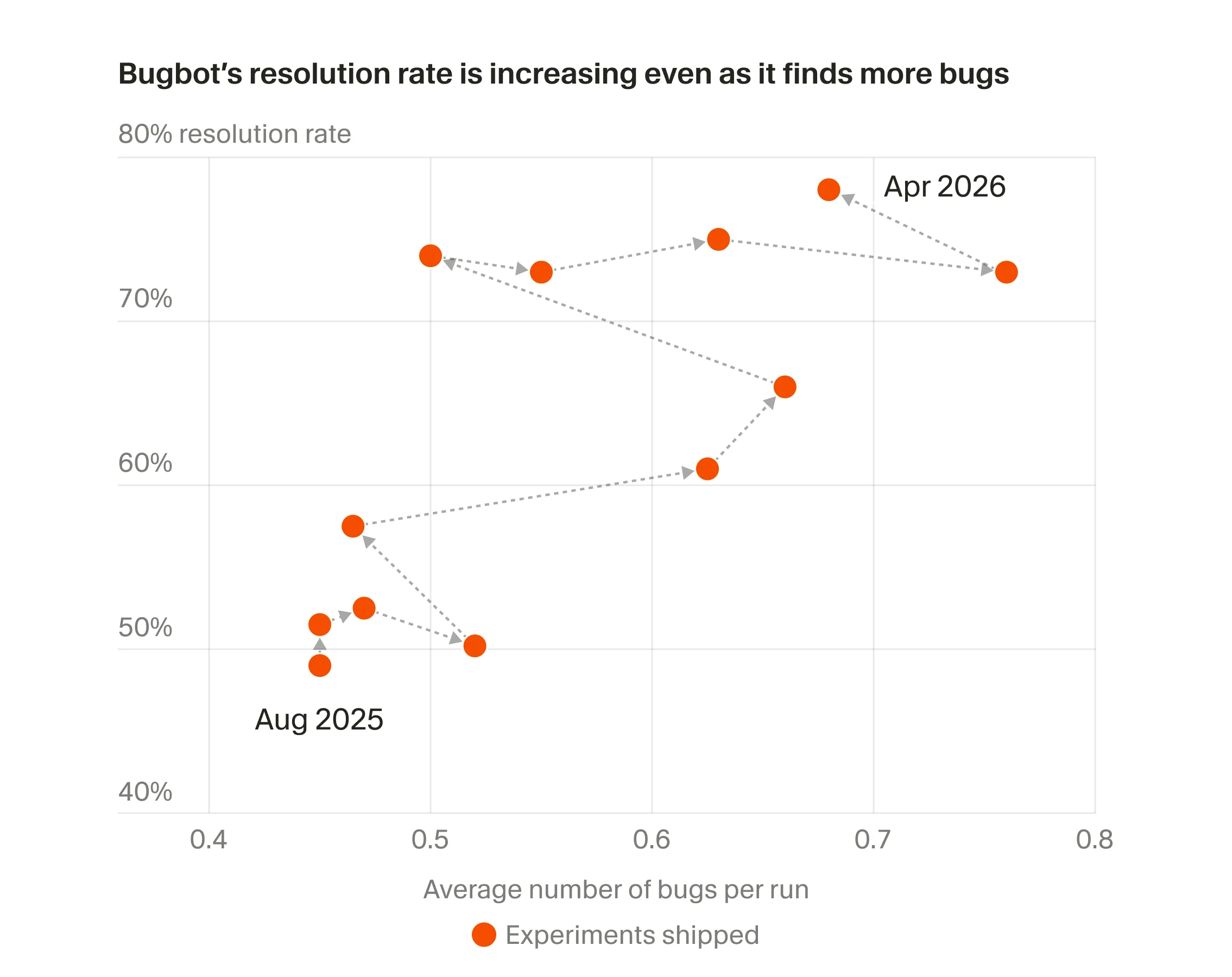
The company’s headline claim is that Bugbot’s resolution rate is now nearing 80 percent, which Cursor says is 15 percentage points higher than the next closest AI code review product. In the company’s comparison table, Bugbot sits at 78.13 percent resolution across 50,310 analyzed pull requests. Greptile is listed at 63.49 percent across 11,419 PRs. CodeRabbit comes in at 48.96 percent, GitHub Copilot at 46.69 percent, Codex at 45.07 percent, and Gemini Code Assist at 30.93 percent.
Those numbers are not just a scoreboard. They reveal something important about how AI review products are being judged in the wild. Cursor says it analyzed public repositories only and used an LLM judge to determine whether a comment had been addressed by the time the PR merged. That means the metric is not “did the model say something?” It is “did the developer act on it before merging?” That distinction is crucial. A code review tool can be impressive and still be ignored. Resolution rate is a much better proxy for whether the product actually fits into developer habits.
That also explains why the company is framing Bugbot as a learning system rather than a fixed detector. The tool is not just looking for patterns in code. It is learning which patterns lead to useful feedback, which issues are worth surfacing, and which comments end up being noise. If that loop works, the product becomes more valuable not only because it catches more bugs, but because it learns the style and priorities of the teams it serves.
Why this is a big deal for AI-assisted development
The industry has spent the last two years obsessing over code generation. That made sense. Generating code is visible, easy to demo, and easy to understand. But production software does not fail because teams cannot generate enough lines. It fails because the wrong lines are merged, the wrong assumptions slip through, or the review process does not catch a subtle issue until it becomes expensive. In other words, the hard part is not always writing code. Often it is knowing what should not be written, or what should be changed before merge.
That is why code review is such an important frontier for AI. Review sits between intention and production. It is where the organization decides whether a change is safe, risky, incomplete, or ready. If a tool can improve that decision, even modestly, it can have an outsized effect on engineering throughput and quality. If it can learn over time, it can become more than a reviewer. It can become a feedback system that understands the codebase, the team, and the kinds of mistakes that matter most in that environment.
Cursor’s learned-rules approach is especially interesting because it turns real developer behavior into training signal. A downvote on a Bugbot comment means the comment was not useful. A reply may explain what was missing or why the suggestion was off. A human reviewer may catch something Bugbot missed. Cursor says those signals can become candidate rules, which can then be promoted or disabled depending on how they perform over time. That is a practical implementation of self-improvement inside a live workflow, not in a lab.
For AI-assisted development, that is the kind of loop that matters most. Developers do not want a system that merely feels intelligent. They want one that gets better in their context. Generic intelligence is useful, but workflow-specific intelligence is what changes how teams operate.
The shift from detection to learning
There is a big difference between a static detector and a learning reviewer. A static detector is trained once, deployed, and then mostly evaluated by how well it matches a benchmark or identifies a class of issues. A learning reviewer uses feedback from actual usage to refine itself. That sounds like a small implementation detail, but in practice it changes the product’s relationship to the codebase. Instead of being an external commentator, the system starts to become part of the team’s operating memory.
That memory matters because every engineering organization has its own standards. What one team treats as a bug, another may accept as a tradeoff. What one team wants flagged aggressively, another may prefer to handle manually. A code review tool that cannot adapt will either be too generic or too annoying. A tool that learns from feedback has a better chance of landing in the sweet spot where it catches real problems without drowning developers in false alarms.
Cursor says more than 110,000 repositories have enabled learning since learned rules launched in beta, generating more than 44,000 learned rules. That suggests the company has already pushed this idea beyond a small experiment. The scale matters because it hints that self-improving review is not a niche feature for a handful of power users. It is becoming a core part of how the product thinks about quality.
That broader implication is important for the whole AI coding market. If one tool can train on the reactions of teams in production-like environments, then product differentiation shifts away from “who can generate the most code” and toward “who can most reliably integrate into the review loop.” That is a more mature market. It rewards systems that respect developer judgment and use it to get better.
What Cursor is really building
Bugbot cannot be understood in isolation. Cursor has been steadily pushing toward a more agentic software-development stack. In its recent “Meet the new Cursor” post, the company described Cursor 3 as a unified workspace for building software with agents. Another post says Cursor agents can now control their own computers. Yet another focuses on securing the codebase with autonomous agents. In other words, Bugbot is not a side project. It is part of a larger bet that the future of software development will be organized around agents that can work longer, in more places, with more context.
That matters because code review is one of the places where this new stack has to prove itself. Generating a patch is not enough. If the system cannot evaluate its own output, or if it leaves too much for the human reviewer to sort out, then the productivity gains collapse under review overhead. Bugbot is Cursor’s answer to that problem. It is an attempt to close the loop between code generation and code validation.
Seen that way, the learned-rules update is not just a feature release. It is infrastructure for the next phase of AI coding. If agents are going to be allowed to do more work on their own, then review systems must become smarter, faster, and more personalized. Otherwise, humans become the bottleneck for every uncertainty the system creates. Cursor is betting that review itself can be automated in a way that preserves trust instead of eroding it.
That is a hard problem. The easier part is building a flashy coding assistant. The harder part is building the machinery that tells developers which parts of the assistant’s output deserve confidence. Bugbot is Cursor’s answer to that harder part.
Why the market is moving this way now
The timing is not accidental. AI coding has matured past the phase where every product was judged by its demo. Teams are now asking more practical questions. How much time does the tool actually save? Does it reduce review fatigue? Does it fit the team’s style? Can it learn from prior mistakes? Can it handle longer-horizon work without making confidence worse?
Those questions are showing up because the easy wins have already been harvested. The industry discovered that models could generate code. Then it discovered that agents could operate tools. Now it is discovering that the quality of the review loop may matter more than the quality of the generation loop. A great patch that never gets merged is not a product. A mediocre patch that gets merged with confidence may be more useful than a brilliant one that requires endless cleanup. AI review tools are being evaluated against that reality.
Cursor’s own benchmarking language reflects that shift. It is not bragging about abstract model intelligence. It is focusing on outcomes that matter to shipping teams: resolution rate, the number of PRs analyzed, and whether the system actually helps developers move forward. That is a good sign for the market. It suggests the conversation is becoming more operational and less hype-driven.
It also suggests that review products will increasingly compete on their ability to understand context. The challenge is not just spotting a null check or a missing test. It is knowing whether that issue matters for this repository, this team, this deployment model, and this moment in the release cycle. A system that learns from feedback is much closer to solving that problem than one that only fires static alerts.
What teams should take from this
For engineering leaders, the practical lesson is straightforward. AI code review is moving from “find bugs” to “learn what bugs your team cares about.” That changes how you should evaluate any tool in this category. Ask not only whether it detects issues, but whether it improves over time. Ask whether it respects the team’s preferences. Ask whether it can be tuned by real feedback instead of only by configuration sliders.
Teams should also think about how they measure success. A high number of comments is not success. A high number of merged suggestions is not necessarily success either. The useful question is whether the tool surfaces the right issues early enough to improve quality without increasing noise. Resolution rate is one way to capture that, but internal developer satisfaction and downstream defect rates matter too. The best AI review systems will eventually have to prove value across all of those dimensions.
There is also a governance angle. Once a system learns from human reactions, it begins to encode organizational norms. That is powerful, but it also means teams should be deliberate about what feedback the system is allowed to learn from. Not every rejected comment is wrong. Not every accepted comment is right. Human bias, team politics, and release pressure can all distort the signal. A self-improving system needs guardrails so that it does not learn the wrong lesson from the wrong week.
In other words, the future of AI review is not just more automation. It is better curation of the feedback that shapes automation.
The broader implication for code quality
The deeper story here is that AI-assisted development is becoming a full lifecycle system. At first, models helped write code. Then they helped reason about code. Now they are helping judge code and improve how judgments are made. That is a much more interesting transition than “faster autocomplete.” It suggests that the machine is moving from a peripheral helper to a participant in the engineering process.
If that continues, then code quality will depend less on one-off reviews and more on continuous learning loops. Bugs will be caught not just by people, but by systems that become more attuned to the codebase over time. The best implementations will probably look less like generic AI products and more like living parts of a team’s engineering culture. They will learn local conventions, understand recurring mistakes, and filter out the noise that humans have learned to ignore.
That future is not automatic, and it is not guaranteed to be smooth. But Bugbot’s learned rules update suggests it is already arriving. The companies that adapt early will get the benefits sooner: better signal, less review fatigue, faster merges, and fewer embarrassing misses. The companies that treat code review as a fixed problem may find themselves outpaced by teams whose review systems keep learning.
That, ultimately, is the significance of Cursor’s announcement. It is not just that a product got better. It is that AI code review is beginning to behave like a system that can grow with the organization instead of merely inspecting it. That is a real milestone for AI-assisted development, and it may be one of the clearest signs yet that the next competitive edge in coding tools will come from trust, context, and learning—not just generation.