La dernière mise à jour de Bugbot par Cursor est bien plus qu’une simple amélioration du produit. Elle marque l’entrée de la révision de code par IA dans une nouvelle phase : l’ère des systèmes de révision capables de s’auto-améliorer. Dans un article publié aujourd’hui, Cursor explique que Bugbot apprend désormais à partir des retours en temps réel et transforme ces retours en règles d’apprentissage. Concrètement, cela signifie que l’outil ne se contente plus d’analyser les pull requests et de signaler des anomalies. Il utilise la manière dont les développeurs réagissent à ces anomalies pour façonner les révisions futures.
Cela peut sembler être un changement subtil, mais il s'agit en réalité d'une évolution majeure dans la manière dont les outils de développement assistés par l'IA évoluent. Au début, le codage assisté par IA consistait principalement en la génération : écrire le code standard, rédiger la fonction, résumer le fichier, suggérer le correctif. Puis vint la vague suivante : des agents capables d’inspecter les dépôts, d’ouvrir des fichiers, d’exécuter des tests et de prendre des mesures. Bugbot ouvre la voie vers la prochaine étape. Il ne se contente pas d’effectuer un travail. Il apprend à partir du travail qu’il accomplit au sein d’un véritable flux de travail d’ingénierie.
Pour les équipes qui livrent des logiciels aujourd’hui, cela importe pour une raison simple : la qualité des revues est devenue un goulot d’étranglement. Plus les organisations génèrent de code, plus elles ont besoin de systèmes capables de distinguer les vrais problèmes du bruit. Si la couche de révision est bruyante, les développeurs l'ignorent. Si elle est trop conservatrice, elle passe à côté des bugs qui comptent. L'argument de Cursor est que Bugbot commence à mieux maîtriser cet équilibre en apprenant de la manière dont les équipes réagissent concrètement, et pas seulement à partir de benchmarks hors ligne.
Ce que les chiffres révèlent selon Cursor
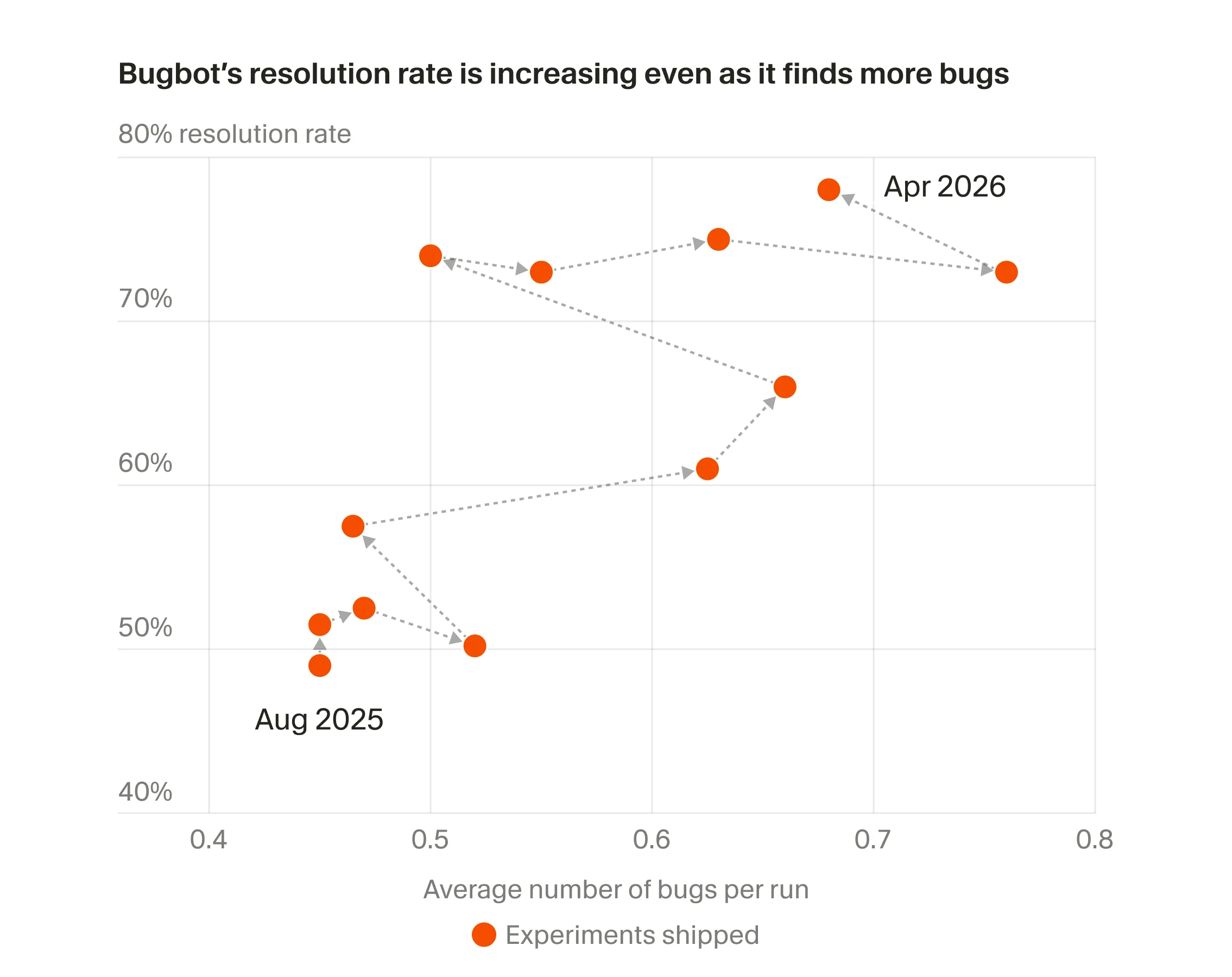
L'argument phare de l'entreprise est que le taux de résolution de Bugbot avoisine désormais les 80 %, ce qui, selon Cursor, représente 15 points de pourcentage de plus que le produit de révision de code par IA le plus proche. Dans le tableau comparatif de l'entreprise, Bugbot affiche un taux de résolution de 78,13 % sur 50 310 pull requests analysées. Greptile affiche un taux de 63,49 % sur 11 419 pull requests. CodeRabbit arrive à 48,96 %, GitHub Copilot à 46,69 %, Codex à 45,07 % et Gemini Code Assist à 30,93 %.
Ces chiffres ne sont pas qu'un simple tableau de bord. Ils révèlent quelque chose d'important sur la manière dont les produits de révision par IA sont jugés en situation réelle. Cursor précise avoir analysé uniquement des dépôts publics et utilisé un juge LLM pour déterminer si un commentaire avait été pris en compte au moment de la fusion de la PR. Cela signifie que la métrique n'est pas « le modèle a-t-il dit quelque chose ? », mais « le développeur a-t-il agi en conséquence avant la fusion ? ». Cette distinction est cruciale. Un outil de révision de code peut être impressionnant tout en étant ignoré. Le taux de résolution est un bien meilleur indicateur pour déterminer si le produit s'intègre réellement aux habitudes des développeurs.
Cela explique également pourquoi l’entreprise présente Bugbot comme un système d’apprentissage plutôt que comme un détecteur figé. L’outil ne se contente pas de rechercher des schémas dans le code. Il apprend quels schémas mènent à des retours utiles, quels problèmes méritent d’être signalés et quels commentaires finissent par n’être que du bruit. Si cette boucle fonctionne, le produit gagne en valeur non seulement parce qu’il détecte davantage de bogues, mais aussi parce qu’il apprend le style et les priorités des équipes qu’il sert.
Pourquoi c'est important pour le développement assisté par l'IA
Le secteur s'est obsédé ces deux dernières années sur la génération de code. Cela avait du sens. La génération de code est visible, facile à démontrer et à comprendre. Mais les logiciels de production ne tombent pas en panne parce que les équipes ne parviennent pas à générer suffisamment de lignes de code. Ils tombent en panne parce que les mauvaises lignes sont fusionnées, que des hypothèses erronées passent inaperçues, ou que le processus de révision ne détecte pas un problème subtil avant qu’il ne devienne coûteux. En d’autres termes, le plus difficile n’est pas toujours d’écrire du code. Souvent, il s’agit de savoir ce qui ne doit pas être écrit, ou ce qui doit être modifié avant la fusion.
C'est pourquoi la révision de code est un domaine si important pour l'IA. La révision se situe entre l'intention et la production. C'est là que l'organisation décide si une modification est sûre, risquée, incomplète ou prête. Si un outil peut améliorer cette décision, même modestement, il peut avoir un effet considérable sur le rendement et la qualité de l'ingénierie. S'il peut apprendre au fil du temps, il peut devenir plus qu'un simple réviseur. Il peut devenir un système de retour d'information qui comprend la base de code, l'équipe et les types d'erreurs qui comptent le plus dans cet environnement.
L'approche par règles apprises de Cursor est particulièrement intéressante car elle transforme le comportement réel des développeurs en signal d'apprentissage. Un vote négatif sur un commentaire de Bugbot signifie que ce commentaire n'était pas utile. Une réponse peut expliquer ce qui manquait ou pourquoi la suggestion était erronée. Un réviseur humain peut repérer quelque chose que Bugbot a manqué. Cursor affirme que ces signaux peuvent devenir des règles candidates, qui peuvent ensuite être activées ou désactivées en fonction de leurs performances au fil du temps. Il s’agit là d’une mise en œuvre pratique de l’auto-amélioration au sein d’un flux de travail réel, et non en laboratoire.
Pour le développement assisté par l'IA, c'est ce type de boucle qui importe le plus. Les développeurs ne veulent pas d'un système qui donne simplement l'impression d'être intelligent. Ils en veulent un qui s'améliore dans leur contexte. L'intelligence générique est utile, mais c'est l'intelligence spécifique au flux de travail qui change la façon dont les équipes opèrent.
Le passage de la détection à l'apprentissage
Il existe une grande différence entre un détecteur statique et un réviseur capable d’apprendre. Un détecteur statique est formé une seule fois, déployé, puis évalué principalement en fonction de sa capacité à correspondre à un benchmark ou à identifier une catégorie de problèmes. Un réviseur capable d’apprendre utilise les retours d’expérience issus de l’utilisation réelle pour s’affiner. Cela peut sembler être un simple détail de mise en œuvre, mais dans la pratique, cela modifie la relation du produit avec la base de code. Au lieu d’être un commentateur externe, le système commence à faire partie de la mémoire opérationnelle de l’équipe.
Cette mémoire est importante car chaque organisation d'ingénierie a ses propres normes. Ce qu'une équipe considère comme un bug, une autre peut l'accepter comme un compromis. Ce qu'une équipe souhaite voir signalé de manière stricte, une autre peut préférer le traiter manuellement. Un outil de révision de code incapable de s'adapter sera soit trop générique, soit trop gênant. Un outil qui apprend à partir des retours a plus de chances d'atteindre le juste équilibre où il détecte les vrais problèmes sans submerger les développeurs de fausses alertes.
Cursor indique que plus de 110 000 dépôts ont activé l'apprentissage depuis le lancement en bêta des règles apprises, générant plus de 44 000 règles apprises. Cela suggère que l'entreprise a déjà poussé cette idée au-delà d'une simple expérience. L'ampleur de ce phénomène est importante car elle laisse entendre que la révision auto-améliorative n'est pas une fonctionnalité de niche réservée à une poignée d'utilisateurs expérimentés. Elle devient un élément central de la façon dont le produit appréhende la qualité.
Cette implication plus large est importante pour l'ensemble du marché du codage par IA. Si un outil peut s'entraîner sur les réactions des équipes dans des environnements de type production, alors la différenciation des produits s'éloigne de la question « qui peut générer le plus de code » pour se diriger vers « qui peut s'intégrer de la manière la plus fiable dans la boucle de révision ». C'est un marché plus mature. Il récompense les systèmes qui respectent le jugement des développeurs et l'utilisent pour s'améliorer.
Ce que Cursor est réellement en train de construire
Bugbot ne peut être compris isolément. Cursor s'est progressivement orienté vers une pile de développement logiciel plus « agentique ». Dans son récent article « Meet the new Cursor », l'entreprise a décrit Cursor 3 comme un espace de travail unifié pour créer des logiciels avec des agents. Un autre article indique que les agents Cursor peuvent désormais contrôler leurs propres ordinateurs. Un autre encore se concentre sur la sécurisation de la base de code à l’aide d’agents autonomes. En d’autres termes, Bugbot n’est pas un projet parallèle. Il s’inscrit dans un pari plus large selon lequel l’avenir du développement logiciel s’organisera autour d’agents capables de travailler plus longtemps, dans davantage d’endroits et avec plus de contexte.
Cela importe car la révision de code est l’un des domaines où cette nouvelle pile doit faire ses preuves. Générer un patch ne suffit pas. Si le système ne peut pas évaluer son propre résultat, ou s’il laisse trop de travail au réviseur humain, alors les gains de productivité s’effondrent sous le poids des frais de révision. Bugbot est la réponse de Cursor à ce problème. C’est une tentative de boucler la boucle entre la génération de code et la validation de code.
Vu sous cet angle, la mise à jour des règles apprises n’est pas seulement une nouvelle fonctionnalité. C’est l’infrastructure pour la prochaine phase du codage par IA. Si l’on veut permettre aux agents d’effectuer davantage de tâches de manière autonome, les systèmes de révision doivent devenir plus intelligents, plus rapides et plus personnalisés. Sinon, les humains deviennent le goulot d’étranglement pour chaque incertitude créée par le système. Cursor parie que la révision elle-même peut être automatisée d’une manière qui préserve la confiance au lieu de l’éroder.
C'est un problème difficile. La partie la plus facile consiste à créer un assistant de codage spectaculaire. La partie la plus difficile consiste à construire le mécanisme qui indique aux développeurs quelles parties de la sortie de l'assistant méritent leur confiance. Bugbot est la réponse de Cursor à cette partie plus difficile.
Pourquoi le marché évolue-t-il ainsi aujourd’hui ?
Le timing n’est pas le fruit du hasard. Le codage par IA a dépassé le stade où chaque produit était jugé sur sa démo. Les équipes posent désormais des questions plus pratiques. Combien de temps l’outil permet-il réellement de gagner ? Réduit-il la fatigue liée à la révision ? Est-il adapté au style de l’équipe ? Peut-il tirer les leçons des erreurs passées ? Peut-il gérer des tâches à plus long terme sans nuire à la confiance ?
Ces questions se posent parce que les gains faciles ont déjà été récoltés. Le secteur a découvert que les modèles pouvaient générer du code. Puis il a découvert que des agents pouvaient utiliser des outils. Aujourd’hui, il découvre que la qualité de la boucle de révision peut avoir plus d’importance que celle de la boucle de génération. Un excellent patch qui n’est jamais fusionné n’est pas un produit. Un patch médiocre fusionné en toute confiance peut s’avérer plus utile qu’un patch brillant nécessitant un nettoyage sans fin. Les outils de révision IA sont évalués à l’aune de cette réalité.
Le langage de benchmarking propre à Cursor reflète cette évolution. Il ne vante pas l’intelligence abstraite des modèles. Il se concentre sur les résultats qui comptent pour les équipes de livraison : le taux de résolution, le nombre de PR analysées, et la question de savoir si le système aide réellement les développeurs à avancer. C’est un bon signe pour le marché. Cela suggère que le débat devient plus opérationnel et moins axé sur le battage médiatique.
Cela suggère également que les produits de révision vont de plus en plus se démarquer par leur capacité à comprendre le contexte. Le défi ne consiste pas seulement à repérer une vérification nulle ou un test manquant. Il s’agit de savoir si ce problème est pertinent pour ce dépôt, cette équipe, ce modèle de déploiement et ce moment précis du cycle de publication. Un système qui apprend à partir des retours est bien plus proche de résoudre ce problème qu’un système qui se contente de déclencher des alertes statiques.
Ce que les équipes doivent retenir
Pour les responsables techniques, la leçon pratique est simple. La révision de code par IA passe de la « recherche de bugs » à l’« apprentissage des bugs qui importent à votre équipe ». Cela change la façon dont vous devez évaluer tout outil de cette catégorie. Demandez-vous non seulement s’il détecte les problèmes, mais aussi s’il s’améliore au fil du temps. Demandez-vous s’il respecte les préférences de l’équipe. Demandez-vous s’il peut être ajusté par de véritables retours d’expérience plutôt que par de simples curseurs de configuration.
Les équipes doivent également réfléchir à la manière dont elles mesurent le succès. Un nombre élevé de commentaires n’est pas synonyme de succès. Un nombre élevé de suggestions fusionnées n’est pas nécessairement un succès non plus. La question utile est de savoir si l’outil met en évidence les bons problèmes suffisamment tôt pour améliorer la qualité sans augmenter le bruit. Le taux de résolution est un moyen de le mesurer, mais la satisfaction interne des développeurs et les taux de défauts en aval comptent également. Les meilleurs systèmes de révision par IA devront à terme prouver leur valeur sur tous ces plans.
Il y a également un aspect de gouvernance. Une fois qu’un système apprend des réactions humaines, il commence à encoder les normes organisationnelles. C’est puissant, mais cela signifie aussi que les équipes doivent réfléchir mûrement aux retours dont le système est autorisé à tirer des enseignements. Tous les commentaires rejetés ne sont pas faux. Tous les commentaires acceptés ne sont pas justes. Les biais humains, les dynamiques d’équipe et la pression liée aux livraisons peuvent tous fausser le signal. Un système capable de s’auto-améliorer a besoin de garde-fous pour ne pas tirer de mauvaises leçons d’une mauvaise semaine.
En d’autres termes, l’avenir de la révision par l’IA ne réside pas seulement dans une automatisation accrue. Il s’agit d’une meilleure sélection des retours d’expérience qui façonnent l’automatisation.
Les implications plus larges pour la qualité du code
Ce qu’il faut retenir ici, c’est que le développement assisté par l’IA est en train de devenir un système couvrant l’ensemble du cycle de vie. Au départ, les modèles aidaient à écrire le code. Puis ils ont aidé à raisonner sur le code. Aujourd’hui, ils aident à évaluer le code et à améliorer la manière dont ces évaluations sont effectuées. Il s’agit d’une transition bien plus intéressante que la simple « saisie semi-automatique plus rapide ». Cela suggère que la machine passe du statut d’aide périphérique à celui de participant au processus d’ingénierie.
Si cette tendance se poursuit, la qualité du code dépendra moins de revues ponctuelles et davantage de boucles d’apprentissage continues. Les bugs seront détectés non seulement par des personnes, mais aussi par des systèmes qui s’adaptent de mieux en mieux au code au fil du temps. Les meilleures implémentations ressembleront probablement moins à des produits d’IA génériques et davantage à des éléments vivants de la culture d’ingénierie d’une équipe. Elles apprendront les conventions locales, comprendront les erreurs récurrentes et filtreront le bruit que les humains ont appris à ignorer.
Cet avenir n’est pas automatique, et il n’est pas garanti qu’il se déroule sans heurts. Mais la mise à jour des règles apprises par Bugbot suggère qu’il est déjà en marche. Les entreprises qui s’adaptent tôt en tireront les bénéfices plus rapidement : un meilleur signal, moins de fatigue liée à la révision, des fusions plus rapides et moins d’erreurs embarrassantes. Les entreprises qui considèrent la révision de code comme un problème figé risquent de se faire distancer par des équipes dont les systèmes de révision continuent d’apprendre.
C'est là, en fin de compte, l'importance de l'annonce de Cursor. Il ne s'agit pas seulement d'un produit qui s'est amélioré. Il s'agit du fait que la révision de code par l'IA commence à se comporter comme un système capable d'évoluer avec l'organisation au lieu de se contenter de l'inspecter. C'est une véritable étape importante pour le développement assisté par l'IA, et c'est peut-être l'un des signes les plus clairs à ce jour que le prochain avantage concurrentiel en matière d'outils de codage viendra de la confiance, du contexte et de l'apprentissage — et pas seulement de la génération.