Claude Mythos Preview n'est pas seulement intéressant parce qu'il est puissant. Il est important car il marque l'arrivée, plus rapide que ne l'avaient prévu de nombreuses équipes, de la prochaine étape du développement assisté par l'IA : un modèle capable d'aider à créer des logiciels, de les comprendre et, dans de bonnes conditions, d'analyser les causes de leurs défaillances. Le rapport de la « red team » d'Anthropic souligne ce point d'une manière difficile à ignorer. L'entreprise affirme que le modèle peut identifier et exploiter des vulnérabilités sur les principaux systèmes d'exploitation et navigateurs lorsqu'on lui en donne l'instruction.
Pour quiconque développe avec l’IA, cela change la donne. Les discussions habituelles sur les assistants de codage se concentrent sur la productivité. Le modèle peut-il rédiger des codes standard ? Peut-il aider à la refactorisation ? Peut-il transformer une instruction vague en un prototype fonctionnel ? Ce sont toujours les bonnes questions, mais Mythos Preview en ajoute une plus difficile : le même système qui aide à livrer du code peut-il également comprendre ce code suffisamment bien pour le casser ? La réponse, du moins selon l’évaluation d’Anthropic, est de plus en plus « oui ».
C'est important car les équipes de développement s'orientent déjà vers des systèmes plus autonomes. Les agents de code peuvent inspecter les dépôts, exécuter des tests, ouvrir des pull requests et interagir avec des outils. Plus ces systèmes deviennent performants, plus ils ressemblent à de véritables opérateurs plutôt qu'à une simple fonction d'autocomplétion. C'est une bonne nouvelle pour la productivité, mais cela signifie aussi que les implications en matière de sécurité liées à l'amélioration des capacités des modèles ne sont plus théoriques. Nous arrivons à un point où l'intelligence des modèles affecte non seulement la vitesse à laquelle le code est écrit, mais aussi la rapidité avec laquelle une faille peut être détectée, reproduite et exploitée.
Le graphique est le message
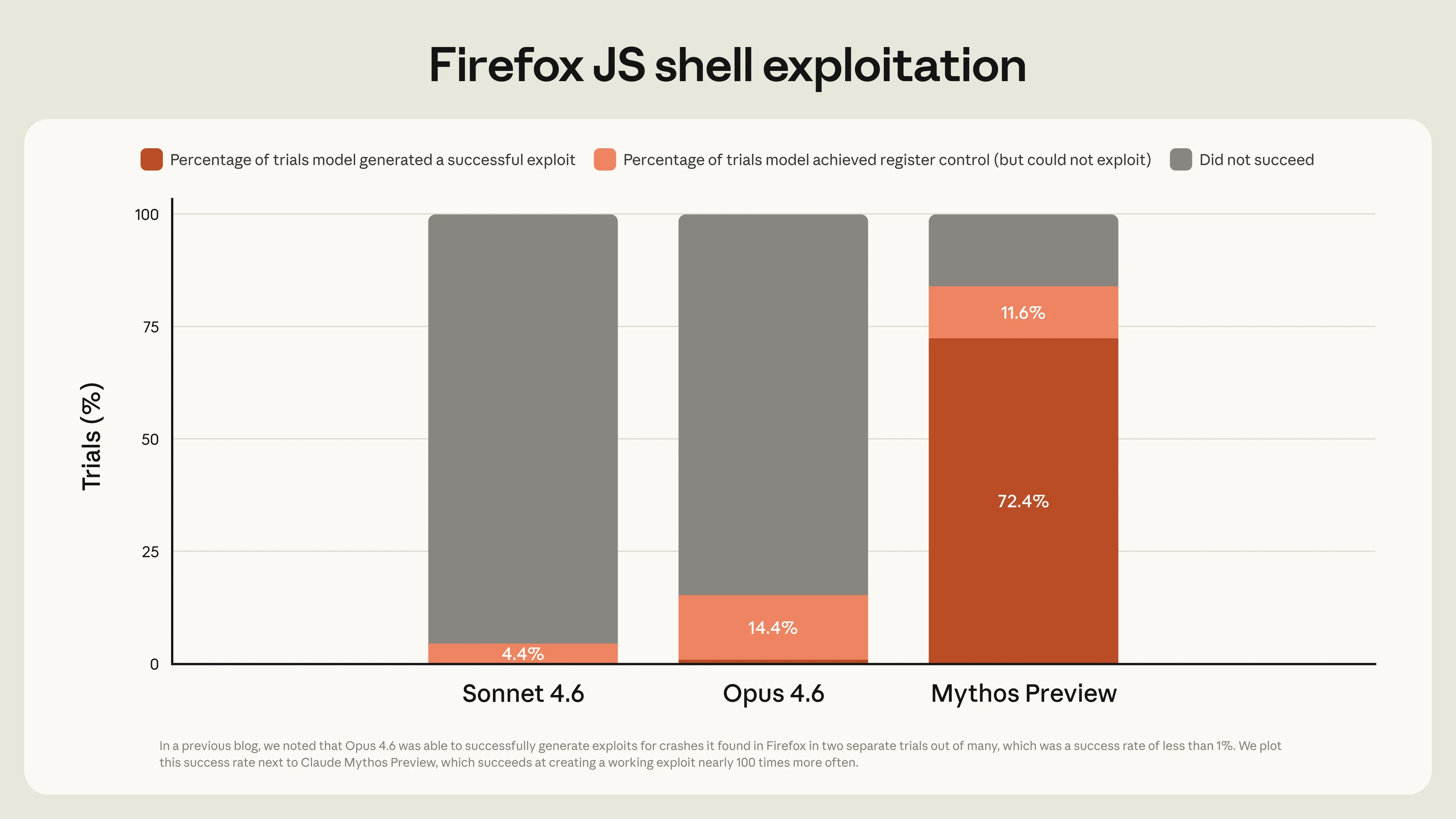
La partie la plus frappante du rapport d'Anthropic n'est pas le texte ; c'est le graphique de référence comparant l'exploitation du shell JavaScript de Firefox entre Sonnet 4.6, Opus 4.6 et Mythos Preview. Les graphiques de ce type sont précieux car ils transforment une affirmation abstraite en un signal concret. Ici, le signal est clair : Mythos Preview est dans une catégorie à part. Le rapport ne présente pas le modèle comme étant simplement plus performant pour répondre aux questions de sécurité. Il le présente comme capable de produire des résultats d'exploitation avec une fréquence et une fiabilité que les générations précédentes ne pouvaient égaler.
Cela importe car le développement d’exploits n’est pas une compétence unique. C’est une chaîne de compétences. Un exploit réussi nécessite souvent de découvrir un bug, d’en comprendre la nature, d’analyser les implications sur la mémoire ou le flux de contrôle, de trouver un chemin stable vers l’exécution, et de réessayer lorsque la première tentative échoue. Si un modèle peut accomplir une partie suffisante de ce travail avec un minimum de supervision, alors l’écart de capacité entre un « assistant utile » et un « système pertinent pour la sécurité » se réduit considérablement.
Concrètement, cela signifie que les tableaux de référence deviennent des artefacts de gouvernance. Lorsqu’un modèle fait preuve d’une avancée significative en matière de capacité d’exploitation, la question n’est pas de savoir si le benchmark est parfait. La question est de savoir sur quels types de workflows cette capacité peut désormais avoir une influence. Pour les développeurs, la réponse va au-delà de la sécurité offensive. Un modèle suffisamment puissant pour explorer des chemins d’exploitation est également suffisamment puissant pour aider à analyser les comportements de plantage, déduire les faiblesses du code et accélérer la correction. C’est cette dualité qui fait de Mythos Preview un repère si important.
Pourquoi les développeurs devraient-ils y prêter attention ?
Les équipes d'ingénierie partent souvent du principe que la cybersécurité est le problème de quelqu'un d'autre, ou du moins qu'elle se situe en aval du flux de développement principal. L'IA remet en cause cette hypothèse. Dès lors qu'un modèle est capable de comprendre une base de code suffisamment en profondeur pour aider à la corriger, il peut également être utilisé pour l'explorer. Les mêmes caractéristiques qui font d’un agent un bon débogueur sont celles qui peuvent le rendre dangereux dans un contexte inapproprié : la patience, l’étendue de ses connaissances, l’accès aux outils et la capacité à persévérer jusqu’à ce qu’il trouve une voie à suivre.
C'est pourquoi le développement assisté par l'IA doit désormais être abordé comme un problème de gouvernance, et non plus seulement comme un problème d'outillage. Si un modèle est autorisé à lire des secrets, à interagir avec des systèmes privilégiés ou à exécuter des commandes dans un environnement étendu, ses capacités deviennent alors un enjeu de sécurité. Plus vous accordez d'autonomie au modèle, plus vous devez réfléchir à la confinement, à l'audit et à l'approbation humaine. Cela est particulièrement vrai pour les équipes adoptant des workflows de codage agentique, où l'assistant est censé aller au-delà de la génération de texte pour entrer dans le domaine de l'exécution d'actions.
Il est tentant de considérer ces systèmes comme des développeurs juniors qui se trouvent être rapides. Cette comparaison n’est utile que si l’on garde à l’esprit les limites d’un développeur junior. Les êtres humains font preuve de prudence, tiennent compte du contexte social et ont une résistance instinctive à répéter mille fois la même chose si la situation semble dangereuse. Un modèle n’a pas cet instinct. Il n’a que les contraintes que vous lui imposez. Si ces contraintes sont faibles, la vitesse du modèle devient alors un handicap autant qu’un avantage.
Pour les organisations, la conclusion est simple mais dérangeante : l’adoption de l’IA et la conception de la sécurité doivent désormais aller de pair. Vous ne pouvez pas traiter un agent de codage comme une couche de commodité distincte tout en supposant que votre posture de sécurité habituelle reste inchangée. L’outil lui-même peut être plus performant que le flux de travail dans lequel il est intégré.
Ce qu'Anthropic dit avoir découvert
Anthropic fait preuve de prudence dans la manière dont elle présente son rapport. L'entreprise indique avoir passé le mois dernier à évaluer Mythos Preview et avoir constaté qu'il était capable d'identifier et d'exploiter des vulnérabilités « zero-day » sur les principaux systèmes d'exploitation et navigateurs. Elle précise également que bon nombre des problèmes découverts n'ont pas encore été corrigés, raison pour laquelle elle ne divulgue pas les détails publiquement. Il s'agit là d'une posture standard de divulgation coordonnée, mais cela confère également du poids au rapport. Ce n'est pas un exercice théorique. L'entreprise affirme que le modèle a détecté des problèmes réels à un point tel que leur divulgation publique serait irresponsable.
Ce type de déclaration devrait retenir l'attention tant des développeurs que des équipes de sécurité. Lorsqu'un modèle de pointe peut mettre au jour des vulnérabilités qui nécessitent encore une discipline de divulgation, les implications ne se limitent pas aux démonstrations de la « red team ». Elles s'étendent à la rapidité avec laquelle d'anciens bugs peuvent être redécouverts, à la facilité avec laquelle ils peuvent être transformés en preuves de concept fonctionnelles, et au temps dont disposent les défenseurs pour réagir avant que l'exploitation ne devienne possible.
Anthropic précise également que ces capacités sont issues d’améliorations générales du code, du raisonnement et de l’autonomie, plutôt que d’un apprentissage explicite des exploits. C’est l’un des détails les plus importants du rapport. Si la capacité d’exploitation peut apparaître comme un sous-produit d’un meilleur codage et d’un meilleur raisonnement, alors le défi de sécurité n’est pas lié à un produit en particulier. Il est lié à l’orientation du domaine. Les mêmes progrès qui améliorent les modèles en ingénierie logicielle peuvent également les rendre plus performants en analyse logicielle adversaire.
Ce point est important pour quiconque conçoit des produits d'IA. Le modèle que vous déployez dans un but précis peut comporter des capacités émergentes qui affectent de nombreux autres domaines. L'évaluation de la sécurité doit tenir compte de ce que le modèle est capable de faire, et pas seulement de ce que vous lui avez demandé de faire.
La nouvelle économie de la découverte des vulnérabilités
La sécurité logicielle a toujours été façonnée par les outils. Les fuzzers, les analyseurs statiques, les pipelines de correctifs, les scanners de secrets et les outils de dépendance existent tous parce que les humains sont trop lents pour tout inspecter à la main. L'IA modifie à nouveau l'économie car elle ajoute le raisonnement et l'adaptation au processus de recherche. Un fuzzer explore les possibilités. Un modèle peut explorer les possibilités, déduire l'intention, lire le code derrière le comportement et proposer un chemin menant du bug à l'exploitation ou du bug à la correction.
C'est cette flexibilité qui rend l'IA si puissante et si déstabilisante. Sur le plan offensif, elle peut réduire le coût de la découverte des vulnérabilités et du développement d'exploits. Sur le plan défensif, elle peut réduire le coût du triage et de la correction. Ce même effet de levier a un double tranchant. Le rôle de l'industrie est de s'assurer que le volet défensif évolue plus rapidement.
Historiquement, des débats similaires ont eu lieu autour du fuzzing. Il y avait des craintes légitimes que les attaquants utilisent des fuzzers pour trouver des bogues plus rapidement. C'est ce qu'ils ont fait. Mais le fuzzing est également devenu une pratique défensive essentielle, car il a aidé les équipes à identifier et à corriger les vulnérabilités à grande échelle. L'IA pourrait suivre la même trajectoire, mais seulement si l'écosystème l'adopte avec rigueur. Sinon, l'asymétrie pourrait pencher trop fortement vers l'attaque avant que la défense ne rattrape son retard.
C'est pourquoi le benchmark présenté dans le rapport d'Anthropic n'est pas qu'une simple curiosité. C'est un indicateur de coût. Si un modèle peut transformer les bugs en tentatives d'exploitation plus efficacement que les générations précédentes, alors le coût d'une attaque contre des systèmes non patchés diminue. Lorsque le coût de l'attaque baisse plus vite que celui de la défense, l'environnement de sécurité se détériore. Si les défenseurs peuvent utiliser les mêmes capacités pour détecter et corriger les problèmes plus rapidement, l'équilibre peut alors être rétabli. C'est la course dans laquelle l'industrie est désormais engagée.
Quels changements pour les workflows de codage assistés par l'IA
Le passage de la saisie semi-automatique au codage agentique n'est pas seulement un changement de produit. C'est un changement d'architecture. Un système capable de prendre des décisions, d'invoquer des outils et d'exécuter des tâches présente une surface d'attaque plus large qu'un système qui se contente de suggérer du texte. Cela est particulièrement vrai lorsque le modèle est intégré à un flux de travail impliquant l'accès à des fichiers, à un shell et à des données en temps réel. Plus le système est utile, plus il peut devenir dangereux s'il est mal contrôlé.
Par conséquent, les équipes de développeurs doivent raisonner par couches. Premièrement, il y a l'accès au modèle : quelles données le modèle peut-il voir ? Deuxièmement, il y a l'accès aux outils : que peut faire le modèle ? Troisièmement, il y a l'accès à l'environnement : où le modèle est autorisé à agir. Chaque couche doit être délimitée de manière aussi stricte que possible. Si un modèle n'a pas besoin d'identifiants de production, il ne doit pas les obtenir. S'il peut fonctionner dans un bac à sable, il doit fonctionner dans un bac à sable. Si un humain doit approuver une modification, le flux de travail doit alors exiger cette approbation.
Cela peut sembler évident, mais de nombreux plans de déploiement de l'IA sont encore conçus en fonction de la commodité plutôt que de la sécurisation. Les équipes veulent que le modèle « fonctionne tout simplement », ce qui implique souvent un accès étendu. Mythos Preview nous rappelle qu'un accès étendu et un raisonnement puissant peuvent former une combinaison risquée. Plus le modèle est capable de comprendre, plus il doit être contrôlé avec soin.
Il y a également un changement culturel en jeu ici. Il faut clairement faire comprendre aux développeurs que l'utilisation de l'IA ne les dégage pas de leur responsabilité en matière de qualité du code ou de sécurité. Au contraire, cela place la barre plus haut. La vérification humaine reste nécessaire, en particulier pour l'authentification, l'autorisation, la cryptographie et tout ce qui est exposé au réseau. L'IA peut apporter son aide dans ces domaines, mais elle ne peut pas être considérée comme l'autorité finale.
Les opportunités défensives sont également bien réelles
Ce serait une erreur de lire le rapport Mythos Preview comme une histoire purement négative. Les mêmes capacités des modèles qui inquiètent les attaquants créent également des opportunités pour les défenseurs. Si un modèle peut raisonner sur les voies d'exploitation, il peut également raisonner sur l'impact des correctifs, le renforcement du code et les étapes de reproduction. Il peut aider au triage, résumer les journaux, expliquer le comportement en cas de plantage et suggérer des solutions potentielles. Dans un workflow mature, cela peut réduire le délai entre la découverte et la correction.
C'est pourquoi la sécurité assistée par modèle pourrait finir par devenir l'une des utilisations les plus précieuses de l'IA de pointe en ingénierie. Non pas parce qu'elle remplace les équipes de sécurité, mais parce qu'elle les aide à se développer. Un analyste humain ne peut inspecter qu'un nombre limité de problèmes par jour. Un workflow IA bien conçu peut aider une équipe à faire le tri parmi le bruit, à hiérarchiser les découvertes les plus dangereuses et à maintenir l'élan pendant la réponse aux incidents. La clé est qu'il doit être déployé en tant qu'assistant contrôlé, et non en tant qu'acteur sans contrainte.
La meilleure version de cet avenir est celle où la capacité offensive conduit à une meilleure conception défensive. Si les modèles peuvent détecter les failles plus rapidement, les équipes logicielles doivent alors réagir par une discipline de correction plus stricte, une meilleure segmentation, une observabilité accrue et un contrôle d'accès plus rigoureux. En d'autres termes, la bonne réponse à une capacité d'attaque accrue n'est pas la peur. C'est une ingénierie plus rigoureuse.
Ce que les équipes de direction doivent faire dès maintenant
Pour les responsables techniques, la liste de contrôle pratique est simple. Limitez les autorisations des agents IA. Ne divulguez pas de secrets dans les contextes des modèles, sauf en cas d’absolue nécessité. Utilisez des environnements sandbox pour l’expérimentation. Consignez les actions de l’agent. Vérifiez manuellement les modifications critiques. Renforcez la CI/CD. Réexaminez la réponse aux incidents. Assurez-vous que l’utilisation des modèles est régie par une politique, et non par simple enthousiasme.
Tout aussi important, alignez les équipes de sécurité et de produit sur une même réalité : les capacités de l'IA évoluent plus rapidement que la plupart des processus de gouvernance internes. Cela signifie que l'ancien cycle « adopter d'abord, sécuriser ensuite » n'est plus acceptable pour les systèmes pouvant toucher au code, à l'infrastructure ou aux données sensibles. Le modèle plus sûr est « définir le périmètre d'abord, observer en continu, puis étendre uniquement lorsque les contrôles ont fait leurs preuves ».
Les organisations qui y parviennent continueront de bénéficier des gains de productivité liés au développement assisté par l'IA. Elles le feront simplement avec une meilleure compréhension des risques. C'est là la véritable leçon du rapport Mythos Preview. La frontière ne se limite plus à des invites plus intelligentes ou à une meilleure génération de code. Il s'agit de systèmes capables d'interagir avec les logiciels à un niveau où la sécurité devient indissociable de leur utilité.
La vision stratégique globale
La conclusion générale est que l'attaque et la défense convergent vers le même type de capacité des modèles. Cela rend l'avenir plus complexe, mais aussi plus honnête. Nous devrions cesser de prétendre que les modèles de codage n'existent que dans la voie de la bienveillance. Un système capable de comprendre le code suffisamment en profondeur pour aider à créer des logiciels peut également le comprendre suffisamment pour le soumettre à des tests de résistance. La seule vraie question est de savoir comment le système est gouverné.
Si le secteur s'y prend bien, l'IA aidera les équipes à livrer plus rapidement et à mieux sécuriser leurs produits. S'il se trompe, les mêmes systèmes qui font gagner du temps réduiront également le temps dont disposent les défenseurs. Le graphique Mythos Preview est un avertissement : la fenêtre de complaisance se referme. Les modèles n'apprennent pas seulement à écrire. Ils apprennent à raisonner, à s'adapter et à opérer tout au long du cycle de vie complet des logiciels.
C'est pourquoi cette histoire dépasse le simple lancement d'un modèle. C'est un aperçu d'un modèle de sécurité pour l'ère de l'IA. L'avenir du développement logiciel ne se résumera pas à ce que l'IA peut générer. Il s'agira de ce que l'IA peut comprendre, de ce qu'elle peut faire, et de la prudence avec laquelle nous choisissons de la laisser agir.