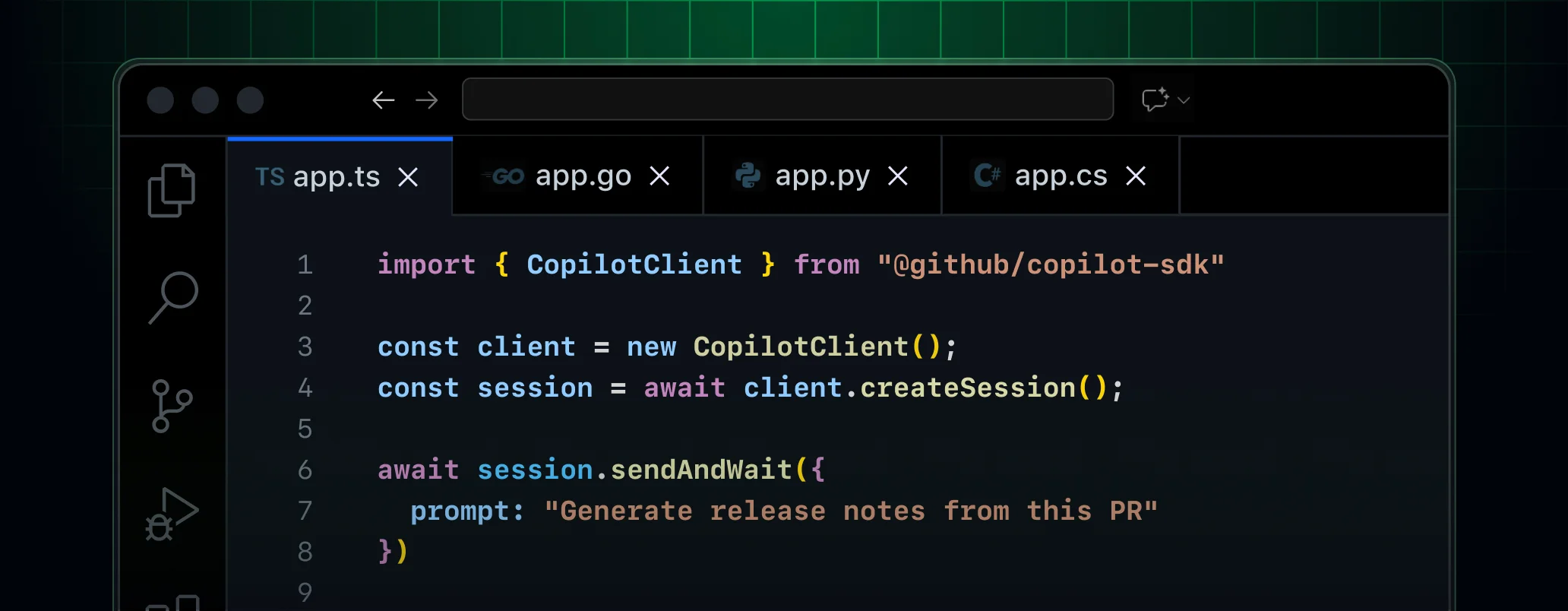
GitHub a franchi une nouvelle étape pour faire du développement assisté par l'IA un outil sur lequel les équipes peuvent réellement s'appuyer. Avec la préversion publique de son SDK Copilot, l'entreprise ne se contente plus de parler d'une simple fenêtre de discussion, d'une barre latérale ou même d'un agent de codage autonome. Elle expose désormais le moteur d'exécution qui sous-tend ces expériences sous la forme d'une couche programmable que les développeurs peuvent intégrer à leurs propres produits, workflows et outils internes.
Ce changement est important car le débat autour du codage assisté par l'IA a largement dépassé le stade de la saisie semi-automatique. Depuis deux ans, le secteur se pose une question plus complexe : que se passe-t-il une fois que le modèle a rédigé le premier jet ? La réponse porte de plus en plus sur l'orchestration : déterminer quand un agent doit planifier, quand il doit faire appel à des outils, quand il doit marquer une pause pour obtenir une validation, et comment son travail doit être tracé, revu et audité.
Le nouveau SDK est la tentative la plus claire de GitHub à ce jour pour commercialiser cette couche d'orchestration. Concrètement, il offre aux développeurs un moyen d’intégrer directement un comportement agentique de type Copilot dans leurs propres applications, plutôt que de rediriger les utilisateurs vers un workflow distinct. GitHub indique que le SDK est désormais disponible en préversion publique et prend en charge Node.js, Python, Go, .NET et Java. Cette large couverture linguistique n’est pas un détail anodin. Elle signale que GitHub souhaite que le SDK soit perçu comme une infrastructure, et non comme une expérience.
D'une fonctionnalité produit à un runtime programmable
L'idée la plus importante de ce lancement n'est pas le nombre de langages ni la liste des commandes d'installation. C'est le fait que GitHub expose le même runtime qui alimente déjà Copilot CLI et l'agent cloud Copilot. Cela signifie que l'entreprise parie que la valeur ne réside pas seulement dans le modèle lui-même, mais dans la machinerie qui l'entoure : boucles de planification, modifications de fichiers, invocation d'outils, sessions à tours multiples et l'échafaudage d'autorisations qui maintient ces sessions sous contrôle.
Pour les développeurs, cela modifie le modèle mental. Au lieu de se demander « Comment mieux interroger le modèle ? », la question la plus utile devient « Que veux-je que cet agent soit capable de faire, et sous quelles contraintes ? ». C'est une façon plus opérationnelle d'envisager l'assistance par l'IA. C'est aussi plus honnête. Les véritables équipes de développement n'ont pas besoin d'un chatbot qui semble intelligent ; elles ont besoin d'un système fiable capable d'inspecter des fichiers, de proposer des modifications, de respecter les limites et de laisser une trace que les humains peuvent examiner.
L'aperçu proposé par GitHub va dans ce sens. Le SDK expose des composants de base pour des outils et des agents personnalisés, ce qui permet aux équipes de définir des actions spécifiques à leur domaine plutôt que de s'appuyer sur un comportement générique. Il prend également en charge les réponses en continu, les pièces jointes de type blob et le traçage OpenTelemetry, autant de signes forts indiquant que l'entreprise s'attend à ce que ces agents fonctionnent au sein de véritables systèmes de production, et pas seulement dans des environnements de test.
Pourquoi cela est-il important pour le développement assisté par l'IA
Il existe ici une tendance plus large qu’il est facile de manquer si l’on se concentre uniquement sur l’annonce de lancement. La première vague d’outils de codage basés sur l’IA concernait principalement la productivité individuelle. L’argumentaire était simple : écrire moins de code standard, générer plus rapidement, passer moins de temps sur des tâches répétitives. La deuxième vague concerne le contrôle du flux de travail. La question n’est plus de savoir si un assistant peut générer du code, mais s’il peut participer en toute sécurité au processus d’ingénierie lui-même.
Cette distinction est importante pour les équipes car les coûts liés à l’IA ne se limitent plus aux erreurs dans le code généré. Ils incluent également l’ambiguïté concernant la propriété, les invites cachées, le contexte manquant et les intégrations fragiles difficiles à observer une fois déployées. Un SDK sérieux doit résoudre ces problèmes. L’accent mis par GitHub sur les autorisations, les limites des outils et la traçabilité suggère qu’il comprend que le marché passe de la nouveauté à la gouvernance.
Il y a également une implication commerciale. Si le SDK est suffisamment performant, les organisations n'utiliseront pas seulement Copilot au sein des produits GitHub. Elles commenceront à créer leurs propres agents spécifiques à certaines tâches pour les flux d'assistance, l'automatisation de la révision de code, le triage des tickets, la réponse aux incidents, les mises à jour de documentation et les portails internes destinés aux développeurs. En d'autres termes, le codage par IA cesse d'être une fonctionnalité que l'on achète pour devenir une couche que l'on compose.
Ce que le SDK offre aux développeurs
GitHub met en avant plusieurs fonctionnalités qui aident à comprendre où cela mène. Les outils et agents personnalisés permettent aux équipes de modéliser leur propre domaine. La personnalisation fine des invites permet aux développeurs d’ajuster des sections de l’invite système sans avoir à tout réécrire de zéro. Le streaming rend l’expérience plus réactive. Les pièces jointes de type blob facilitent la transmission de captures d’écran ou d’entrées binaires aux agents. OpenTelemetry aide à relier l’activité des agents au reste de la pile d’observabilité d’une application. Et le cadre d’autorisations permet de bloquer les opérations sensibles ou d’exempter les actions en lecture seule de validations inutiles.
Le détail peut-être le plus important pour les entreprises est la prise en charge du « bring-your-own-key » (BYOK). Cela est important car de nombreuses organisations ne souhaitent pas s'engager dans une énième relation de compte de type « boîte noire ». Elles veulent contrôler le choix du modèle, la facturation et la politique. La prise en charge BYOK du SDK facilite l'intégration des workflows d'agents dans les modèles d'approvisionnement et de conformité existants, au lieu d'imposer à tous un parcours auprès d'un seul fournisseur.
L'inconvénient est que cela relève également le niveau d'exigence en matière d'ingénierie. Une fois qu'un agent est intégré à un produit ou à un workflow, on hérite de toutes les responsabilités habituelles de la conception logicielle : gestion du cycle de vie, gestion des défaillances, audits de sécurité, limites de débit, journalisation et planification des retours en arrière. Un agent de codage capable d'agir est plus puissant qu'un assistant de codage qui ne peut que suggérer, mais il doit également être traité davantage comme un service que comme un jouet.
La réalité : l'orchestration devient le produit
C'est pourquoi cette version semble importante même au-delà de l'écosystème GitHub. Elle reflète une transition plus large du secteur. Le marché prend lentement conscience que le modèle n'est qu'une partie du système. Le véritable avantage provient de la couche d'orchestration environnante : utilisation des outils, limites de mémoire, flux d'approbation, auditabilité et l'expérience développeur pour contrôler tout cela.
Pour le développement assisté par l'IA, c'est une bonne nouvelle. Cela signifie que le débat mûrit. Les équipes s'éloignent des déclarations générales sur le remplacement des ingénieurs pour se tourner vers des questions pratiques sur la manière de rendre les ingénieurs plus efficaces sans perdre le contrôle du code. Un bon SDK peut y contribuer en transformant des capacités d'IA vagues en quelque chose de mesurable, de modulable et de gérable.
Le SDK Copilot de GitHub ne résout pas tous les problèmes liés au codage par l'IA, et il n'en est encore qu'au stade de préversion publique. Mais il marque une étape utile sur le marché. L'époque où l'on se demandait si les agents pouvaient écrire du code est révolue. La prochaine étape consiste à déterminer s'ils peuvent être intégrés à la pile d'ingénierie d'une manière qui inspire confiance aux développeurs. C'est là le problème le plus difficile — et celui qui importe le plus.